High performance single-threaded access to SimpleDB
Last month, Amazon published a code sample which demonstrated the use of SimpleDB as a repository for S3 object metadata. This code sample would probably have gone almost completely unnoticed if it were not for one detail: Using a pool of 34 threads in Java, the code sample sustained 300 SimpleDB operations per second when running on a small EC2 instance. Only 300? We can do better than that...First, rather than using multiple threads, I used a single thread with several TCP connections and non-blocking I/O. The most difficult part of this is the HTTP client code; but fortunately I already had event-driven HTTP client code available which I wrote in order to allow the tarsnap server to access Amazon S3.
Second, I rejected Amazon's recommendation to use exponential back-off when retrying failed SimpleDB requests. While this is appropriate for an application which makes one SimpleDB request at once, it is a poor strategy when making a large number of requests (e.g., when fetching attributes for all of the items returned by a Query operation) for two reasons:
- In the common scenario where request results are not useful until all the requests have been serviced (e.g., when the results are being used to construct a web page), delaying the retry of a failed request by up to 400 ms (as Amazon suggests) is likely to delay the entire operation by up to 400ms, since all the other requests will be done long before the request being retried.
- If multiple threads (34 in Amazon's example) are each issuing one request at once, having one thread wait 400 ms before retrying a request will have little impact on the load placed upon SimpleDB, since the remaining threads (in Amazon's example, 33 out of 34) will continue to issue requests at the same rate.
A better approach, and the one I used, is inspired by TCP congestion control: Allow no more than cwnd simultaneous requests, where cwnd increases gradually if there is no congestion but is cut in half if congestion is detected. My implementation differs from TCP congestion control on the following minor points:
- I do not use slow-start; that is, I start by increasing cwnd linearly rather than exponentially. Experiments indicated that using slow-start tended to result in a large number of requests failing due to timeouts but then clogging up the network as very late responses were sent back by SimpleDB.
- I always use slow-restart; that is, if the number of simultaneous connections drops below cwnd, new connections are started "slowly" (that is, exponentially) rather than all at once. This reduces the danger of severe congestion if other systems have increased their SimpleDB request rate during the period when we were less demanding; and does not run into the problems encountered with slow-start, since when using slow-restart we have a ssthresh value which we know is attainable under good conditions.
- When congestion is detected, the slow-start threshold ssthresh is set to half of the number of requests which were in-flight when the failed request was issued. This is necessary to handle the case where multiple requests fail but one of the failures isn't detected until a network timeout occurs a short time later -- at which point the number of in-flight requests will be significantly lower than the number which triggered the failure.
- When a request fails (either due to an HTTP connection failure, or if an HTTP 5xx status code is received), it is queued to be reissued later (up to a maximum of 5 attempts). In TCP, lost packets must be retransmitted before any progress can be made; but with SimpleDB each request is independent, so there's no need to wait for requests to be retried before making "later" requests.
So how well does this work? I tested with the following sequence of operations from an EC2 small instance and logged the number of requests serviced per second along with the number of simultaneous connections:
- Put 10,000 items, each having 2 attributes.
- Issue a Query with a QueryExpression of "" (which all items match); and for each returned item, Get one of the attributes.
- Issue a Query involving one of the attributes, which is matched by 6971 items; and for each returned item, Get the other attribute.
- Issue a Query involving both attributes, which is matched by 9900 items; and for each returned item, Get both attributes.
- Delete all 10,000 items.
I then plotted the results of this test, with the number of requests serviced per second in green and the number of simultaneous connections in red:
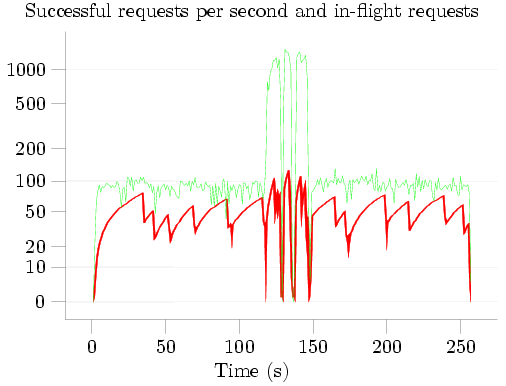
The five phases of the test are clearly visible: about 120 seconds spent Putting items to SimpleDB; three queries lasting approximately 9 seconds, 5 seconds, and 7 seconds respectively; and about 110 seconds Deleting the items from SimpleDB. The characteristic 'sawtooth' pattern of additive-increase-multiplicative-decrease (AIMD) congestion control is visible in red; note that when the first query starts, the congestion window quickly increases -- SimpleDB can apparently handle more simultaneous Gets than simultaneous Puts -- and the successful request rate increases correspondingly until it reached SimpleDB's limit at about 1300 requests per second.
During the initial Put phase, SimpleDB reported a total BoxUsage of 0.219923 hours, i.e., 791 seconds. Given that this phase lasted only 120 seconds, the BoxUsage would indicate that an average of 6 SimpleDB nodes were busy handling the PutAttributes requests at any given time. Even more extreme than this, during the three Queries, when about 1300 GetAttributes calls were being successfully handled each second, the BoxUsage values indicate that an average of over 40 SimpleDB nodes were busy handling the GetAttributes requests. I am, to say the least, rather skeptical of the veracity of these numbers; but as I have already commented on BoxUsage I'll say no more about this.
While a couple of questions remain -- why did I not receive any 503 Service Unavailable errors? Could performance be improved by connecting to several different SimpleDB IP addresses instead of just one? -- one thing is very clear: Using a single thread, non-blocking I/O, and a good congestion control algorithm, it's possible for a single small EC2 instance to successfully issue 50-100 PutAttributes or DeleteAttributes calls per second, and about 1300 GetAttributes calls per second -- over 4 times the rate for which Amazon's code sample received so much attention.