Software development final exam answers: Part 3
These are the answers, along with some commentary, for part 3 (Mathematics) of my software development final exam. I apologize for the very lengthy delay in getting this posted; unfortunately my travel in late November and early December, along with urgent work I needed to get done immediately before and afterwards, kept me away from marking the reponses I received.Each question was graded out of 5, with points awarded for different parts of each question as described below; in some cases I awarded partial marks (e.g., 2 of 3 possible marks for part of a question) when someone had the right general idea but missed some details.
Mathematics
-
Question:
You have a spam filter which marks 99% of spam messages as spam, and 99% of
non-spam messages as non-spam (and gets the other 1% wrong). 95% of the
email arriving at your server is spam. What fraction of messages in your
inbox are spam? What fraction of messages in your spam folder are not spam?
Answer: Of the incoming email, 4.95% is non-spam and not marked as spam; 0.05% is non-spam which is marked as spam; 0.95% is spam which is not marked as spam; and 94.05% is spam which is marked as spam. Consequently the fraction of mail not marked as spam is 5.90% and the fraction of mail marked as spam is 94.10%. Thus the fraction of messages in your inbox which are spam is 0.95% / 5.90% = 16%; and the fraction of messages in your spam folder which are not spam is 0.05% / 94.10% = 0.053%.
Grading: I awarded 5 marks for the correct answer (both parts); 3 marks to people who answered the first half of the question but not the second half.
Commentary: The average score on this question was 3.2/5, which I found disappointingly low: This question requires nothing more than high school probability, and I expected that almost everybody would receive full marks.
The most common error, oddly enough, was to answer the first half of the question — what fraction of messages in your inbox are spam — but ignore the second half of the question. In a sense I feel bad about taking off marks for that, since being able to answer the first half of the question shows an understanding of probability; but the topic of this part is mathematics, and mathematics is nothing without attention to detail.
In addition to it playing the role of "giveaway" question on this part, I included this question as a test of simple probability. Being able to perform these sorts of simple computations is useful in all sorts of contexts — How likely is it that your RAID array will have a second disk failure before you get around to replacing the first failed disk? If it takes 15 minutes to write an intelligent comment and your comment submission links are invalidated every time your server reboots, how many intelligent comments are you losing? If your website doesn't work with Internet Explorer 6, how much money are you losing? — so I couldn't write an exam without inculding at least one such question.
-
Question:
What is the difference between a hash function [EDIT: make that a
cryptographic hash function] and a message authentication code?
Answer: A cryptographic hash function has no key and guarantees only that it is infeasible to generate two different messages with the same hash. A message authentication code has a key and guarantees that it is infeasible given access to a MAC-computing oracle (but not access to the key itself) to generate any (message, MAC) pair for which the message was not input to the oracle.
Grading: I awarded 5 marks for the collision-free vs. unforgeable distinction mentioned above; or 2 marks for merely pointing out that MACs have keys.
Commentary: The average score on this question was 2.0/5, which was in line with my expectations. A large majority of respondents were aware that MACs have keys, but under 20% pointed out the more subtle difference between the two constructs.
When I first posted this set of questions, many people asked why I included a question about cryptography under the banner of "mathematics". Beyond the trivial answers, that I consider cryptography to be a field of mathematics, and that I constructed this exam by composing questions first and organizing them into four parts later, there is an essential similarity: As I wrote in an earlier blog post, computer security and mathematics both require that you get all the details right. Saying that something "looks" right isn't good enough; you need to be able to start from the basic building blocks and ask what you know about them.
And this is probably the most common thing people get wrong: The idiom "hash(key || data)" looks very appealing, yet with some hash functions (anything using the Merkle-Damgård construction, for example) it is trivially broken as a message authentication code. Over the years I've lost count of the number of websites and applications I've seen making this mistake; I have no hesitation in saying that if you don't know the difference between collision-free and unforgeable and that they are properties held by hashes and message authentication codes respectively, you should not be writing any software which uses either of them.
-
Question:
Define
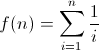
Find
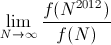
Show work — a formal proof is not required, but I'd like to see more than just the answer. (2-3 sentences is probably about right.)Answer: The function f(n) is the harmonic series, which is well known to be equal to ln(n) + γ + o(1), where γ is the Euler-Mascheroni constant. It is also possible to trivially bound ln(n) < f(n) < ln(n) + 1 by comparing the sum to the integral of 1/x from 1 to n.
The limit we want is thus:
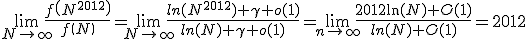
Grading: I awarded 3 marks for remembering and/or figuring out that f(n) is asymptotically ln(n), or 1 mark for knowing that it is the harmonic series without knowing the sum. I awarded 2 marks for getting the final answer.
Commentary: The average score on this question was 2.5/5, which was in line with my expectations. The step which people had difficulty with was identifying the sum; the vast majority of people who recognized that f(n) is asymptotically ln(n) managed to follow through with the limit and get the final answer.
This is an easy calculus question; I would not be surprised to find it on a midterm or final exam for a 1st year course. While many "self-taught" developers will not have taken such a course, any post-secondary program in computer science or software development should include this material.
It's hard to overstate the wide relevance of basic calculus to software development — at least, if you want to make sure you produce consistently good code rather than merely writing code which you hope will work. From analysing algorithms to predicting the economic behaviour of online games to machine learning to physical modeling — Angry Birds, anyone? — to understanding server performance to predicting the reliabilty of distributed systems, calculus is applicable in a vast range of areas, and no developer should be without it.
-
Question:
You are testing two different versions of a website (A and B) to determine
which one yields a higher sign-up rate. You know that if version B is 10%
more effective than version A, then once N visitors have reached your site
there is a 90% chance that version B will have produced more signups than
version A. Approximately how many visitors would you need in order to have
that same 90% chance, if version B is instead only 5% more effective than
version A?
Answer: From the values given, we are guaranteed that N is large enough that the normal approximation can be safely used. With the normal distribution, the standard error is proportional to the inverse square root of the sample size; and to reliably detect an effect you need the standard error to be of the same order as the effect size.
Consequently, moving from a 10% effect to a 5% effect requires that the sample size increase by a factor of (10 / 5)^2 = 4; thus you would need a sample size of approximately 4 N.Grading: I awarded up to 2 marks for saying something sensible about the statistics (normal distribution, standard error needing to be half as large, etc.) and 3 marks for getting the right answer.
Commentary: The average score on this question was 1.3/5, which I found to be very disappointingly low. Most people simply didn't have a clue; and very few people were able to say anything reasonable without being able to provide a complete solution.
This is very basic statistics, and figuring out what sample size you need in order to detect a signal — or alternatively, figuring out whether a signal you're observing is statistically significant — is very much a real-world problem. Web developers keep on talking about doing A-B tests on their sites, but without having some understanding of statistics it's easy to waste a lot of time either over-testing or making changes which you lack meaningful evidence to support.
I was particularly surprised at the poor performance on this question in light of the timing: I posted the exam just a few weeks before the US election. With so much attention being given to polls (and to five thirty-eight in particular) I expected greater awareness of sample sizes — and in particular, that doubling the sample size does not cut the margin of error in half.
-
Question:
Why should a message be "padded" (and not just with zeroes) before being
encrypted or signed using RSA?
Answer: RSA is an automorphism in the multiplicative group mod N: E(A * B) = E(A) * E(B). As a result, unpadded (or zero-padded) RSA is malleable, and generating some valid messages can make it possible to decrypt or forge other valid messages.
There are also generic attacks against deterministic public-key encryption (given E(x), you can determine if x = M for a specified M, by computing E(M) and comparing), and attacks against encryption with small exponents and/or to multiple recipients with different moduli (if you are given or can reconstruct a value x^e which has not been reduced modulo any primes, you can take the eth root); but these do not apply to signatures.Grading: I awarded full marks for showing awareness of the algebraic structure and resulting malleability (even if that precise terminology was not used). I awarded partial marks for mentioning attacks which are relevant only to encryption and not to signing.
Commentary: The average mark on this part was 1.2/5, which was roughly in line with my expectations. Only a few people received full marks; most people offered no answer, and of those who gave answers most only mentioned the possibility of a "brute force" attack on encryption by encrypting every possible short message and comparing the encrypted values.
Rather perplexingly, a large number of people thought that using RSA without padding could result in the private key being revealed. While it is true that using RSA without padding can allow an attacker to decrypt or sign smooth messages, this is not the same as revealing the private key; so I'm not sure quite where that misconception originated.
I expected to hear complaints about the presence of this question on the exam, and in this I was not disappointed. I maintain nevertheless that this question deserves its place: Where the first question of this exam part was intended to be something everybody should be able to answer, this last question — like the last question of part 1 — was intended to test whether people could take what they knew and reason about it. I don't expect non-cryptographers to be aware of the state of the art in attacks on (mis-implemented) RSA; but I would like them to be able to ask themselves "what do we know about modular arithmetic?" and "what could go wrong here?" — that last question, of course, being absolutely vital to anyone concerned with security.
For this entire part, the average combined score was 10.1/25; approximately equal numbers of people received scores in each of the ranges 0-6, 7-9, 10-14, and 15-25.
I will be posting my answers, along with commentary, to part 4 of the exam — Networking and systems — shortly after I finish marking the responses I have received to it.